![Приглашаем на GRAND DRIVE PARTY 2024]()
Приглашаем на GRAND DRIVE PARTY 2024
23.11.24
0
7057

Как появились нейронные сети?

За последние 10 лет, благодаря методу так называемого глубокого обучения, мы получили самые лучшие системы искусственного интеллекта — например, распознаватели речи на смартфонах или последний автоматический переводчик Google. Глубокое обучение, по сути, стало новым течением в уже известных нейронных сетях, которые входили в моду и выходили на протяжении более 70 лет. Впервые нейронные сети предложили Уоррен Маккалоу и Уолтер Питтс в 1994 году, два исследователя Чикагского университета. В 1952 году они перешли работать в Массачусетский технологический институт, чтобы заложить основу для первой кафедры когнитологии.
Нейронные сети были одним из основных направлений исследований как в нейробиологии, так и информатике до 1969 года, когда, если верить легендам, их прикончили математики Массачусетского технологического института Марвин Мински и Сеймур Паперт, которые через год стали соруководителями новой лаборатории искусственного интеллекта MIT.
Возрождение этот метод пережил в 1980-х, слегка ушел в тень в первом десятилетии нового века и с фанфарами вернулся во втором, на гребне невероятного развития графических чипов и их обрабатывающей мощности.
«Есть мнение, что идеи в науке — это как эпидемии вирусов», говорит Томазо Поджио, профессор когнитологии и наук о мозге в MIT. «Существует, по всей видимости, пять или шесть основных штаммов вирусов гриппа, и один из них возвращается с завидной периодичностью в 25 лет. Люди заражаются, приобретают иммунитет и не болеют следующие 25 лет. Затем появляется новое поколение, готовое к тому, чтобы заразиться тем же штаммом вируса. В науке же люди влюбляются в идею, она всех сводит с ума, затем ее забивают до смерти и приобретают иммунитет к ней — устают от нее. У идей должна быть подобная периодичность».
Весомые вопросы
Нейронные сети представляют собой способ машинного обучения, когда компьютер учится выполнять некоторые задачи, анализируя тренировочные примеры. Как правило, эти примеры вручную помечаются заранее. Система распознавания объектов, например, может впитать тысячи меченых изображений автомобилей, домов, кофейных чашек и так далее, и затем сможет находить визуальные образы в этих изображениях, которые последовательно коррелируют с определенными метками.
Нейронную сеть часто сравнивают с человеческим мозгом, в котором тоже есть такие сети, состоящие из тысяч или миллионов простых обрабатывающих узлов, которые тесно связаны между собой. Большинство современных нейронных сетей организованы в слои узлов, и данные проходят через них только в одном направлении. Отдельный узел может быть связан с несколькими узлами в слое под ним, из которого он получает данные, и несколькими узлами в слое выше, в которые он данные передает.
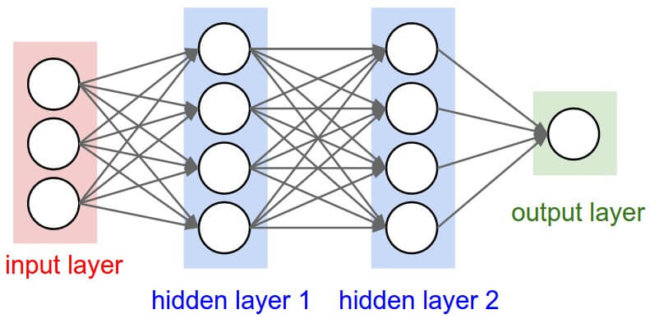
Каждой из этих входящих связей узел присваивает номер — «вес». Когда сеть активна, узел получает разные наборы данных — разные числа — по каждому из этих соединений и умножает на соответствующий вес. Затем он суммирует получившиеся результаты, образуя единое число. Если это число ниже порогового значения, узел не передает данные в следующий слой. Если же число превосходит пороговое значение, узел «активируется», посылая число — сумму взвешенных входных данных — на все исходящие соединения.
Когда нейронная сеть тренируется, все ее веса и пороговые значения изначально устанавливаются в случайном порядке. Тренировочные данные подаются в нижний слой — входной — и проходят через последующие слои, умножаясь и суммируясь сложным образом, пока, наконец, не прибудут, уже преобразованные, в выходной слой. Во время обучения веса и пороговые значения постоянно подстраиваются, пока тренировочные данные с одинаковыми метками не станут давать сходные выводы.
Разум и машины
Нейронные сети, описанные Маккалоу и Питтсом в 1944 году, имели и пороговые значения, и веса, но не были организованы послойно, а ученые не задавали никакого конкретного механизма обучения. Но Маккалоу и Питтс показали, что нейронная сеть могла бы, в принципе, рассчитать любую функцию, как любой цифровой компьютер. Результат был больше из области нейробиологии, чем информатики: нужно было предположить, что человеческий мозг можно рассматривать как вычислительное устройство.
Нейронные сети продолжают оставаться ценным инструментом для нейробиологических исследований. Например, отдельные слои сети или правила настройки весов и пороговых значений воспроизвели наблюдаемые особенности человеческой нейроанатомии и когнитивных функций, а значит, коснулись того, как мозг обрабатывает информацию.
Первая обучаемая нейронная сеть, «Перцептрон» (или «Персептрон»), была продемонстрирована психологом Корнеллского университета Франком Розенблаттом в 1957 году. Дизайн «Перцептрона» был похож на современную нейронную сеть, за исключением того, что у него был один слой с регулируемыми весами и порогами, зажатый между входным и выходным слоями.
«Перцептроны» активно исследовались в психологии и информатике до 1959 года, когда Мински и Паперт опубликовали книгу под названием «Перцептроны», которая показала, что произведение вполне обычных вычислений на персептронах было непрактичным с точки зрения временных затрат.

«Конечно, все ограничения как бы исчезают, если сделать машины чуть более сложными», например, в два слоя», говорит Поджио. Но в то время книга оказала сдерживающий эффект на исследования нейронных сетей.
«Эти вещи стоит рассматривать в историческом контексте», говорит Поджио. «Доказательство строилось для программирования на таких языках, как Lisp. Незадолго до этого люди спокойно использовали аналоговые компьютеры. Было не совсем ясно на тот момент, к чему вообще приведет программирование. Думаю, они слегка переборщили, но, как и всегда, нельзя делить все на черное и белое. Если рассматривать это как состязание между аналоговым вычислением и цифровым вычислением, тогда они боролись за то, что было нужно».
Периодичность
К 1980-м годам, однако, ученые разработали алгоритмы для модификации весов нейронных сетей и пороговых значений, которые были достаточно эффективны для сетей с больше чем одним слоем, устранив много ограничений, определенных Мински и Папертом. Эта область пережила Ренессанс.
Но с разумной точки зрения в нейронных сетях чего-то недоставало. Достаточно длительная тренировка могла привести к пересмотру настроек сети до тех пор, что она начнет классифицировать данные полезным образом, но что эти настройки означают? На какие особенности изображения смотрит распознаватель объектов и как он собирает их по частям, чтобы сформировать визуальные сигнатуры машин, домов и чашек кофе? Изучение весов отдельных соединений не даст ответа на этот вопрос.
В последние годы компьютерные ученые начали придумывать хитроумные методы для определения аналитических стратегий, принятых нейронными сетями. Но в 1980-х годах стратегии этих сетей были непонятными. Поэтому на рубеже веков нейронные сети были вытеснены векторными машинами, альтернативным подходом к машинному обучению, основанном на чистой и элегантной математике.
Недавний всплеск интереса к нейронным сетям — революция глубокого обучения — обязан индустрии компьютерных игр. Сложная графическая составляющая и быстрый темп современных видеоигр требует аппаратного обеспечения, которое сможет угнаться за тенденцией, в результате чего появился GPU (графический процессор) с тысячами относительно простых обрабатывающих ядер на одном чипе. Очень скоро ученые поняли, что архитектура графического процессора прекрасно подходит для нейронных сетей.
Современные графические процессоры позволили выстроить сети 1960-х годов и двух- и трехслойные сети 1980-х в букеты из 10-, 15- и даже 50-слойные сети сегодняшнего дня. Вот за что отвечает слово «глубокое» в «глубоком обучении». К глубине сети. В настоящее время глубокое обучение отвечает за наиболее эффективные системы практически во всех областях исследований искусственного интеллекта.
Под капюшоном
Непрозрачность сетей все еще беспокоит теоретиков, но и на этом фронте есть подвижки. Поджио руководит исследовательской программой на тему теоретических основ интеллекта. Не так давно Поджио и его коллеги выпустили теоретическое исследование нейронных сетей в трех частях.
Первая часть, которая была опубликована в прошлом месяце в International Journal of Automation and Computing, адресовано диапазону вычислений, которые могут проводить сети глубокого обучения, и тому, когда глубокие сети имеют преимущества над неглубокими. Части два и три, которые были выпущены в виде докладов, адресованы проблемам глобальной оптимизации, то есть гарантирования, что сеть будет находить настройки, которые лучше всего подходят к ее обучающим данным, а также случаев, когда сеть настолько хорошо понимает специфику обучающих ее данных, что не может обобщать другие проявления тех же категорий.
Впереди еще много теоретических вопросов, ответы на которые придется дать. Но есть надежда, что нейронные сети смогут, наконец, разорвать цикл поколений, которые ввергают их то в жар, то в холод.